Certains termes, tel le mot «format», sont fréquemment utilisés avec imprécision dans le domaine audiovisuel ; la distinction, toujours actuelle et pertinente, entre film et vidéo, disparaît souvent à l’usage, peut-être parce que le langage courant se réfère au contenu uniquement alors que dans les questions de conservation, la forme (technique) est essentielle. Pour décrire clairement les sujets techniques complexes traités ici et les défis de la conservation numérique, le vocabulaire employé doit être très précis. La suite du présent chapitre explique quelques-unes des notions les plus importantes.
Cassette vidéo
Une cassette vidéo est faite d’une bande magnétique dans une cassette de matière plastique, dotée d’une bobine preneuse (ou bobine réceptrice ) et une bobine dérouleuse (émettrice), qui permet la lecture dans un appareil de lecture spécifique. La bande peut selon les spécificités du format être d’une longueur, largeur et épaisseur différentes ainsi qu’avoir des propriétés magnétiques différentes (soit la force coercitive qui permet de magnétiser la bande dans la polarité souhaitée). La configuration de la bande est calée sur le signal vidéo d’un format vidéo déterminé.
Videoplayer, Videorecorder
À l’origine, un videoplayer et un videorecorder désignaient un appareil de lecture et d’enregistrement. Aujourd’hui, le terme désigne aussi un programme informatique (par ex. un software-player), qui peut enregistrer un signal vidéo numérique ou le faire lire depuis un fichier et l’afficher à nouveau sur un moniteur PC ou sur un projecteur. Un signal analogique doit d’abord être converti avec un convertisseur A/D (Analogique/Numérique) pour pouvoir être traité par le programme adéquat.
Largeur de bande / débit du signal d’image vidéo
La largeur de bande d’un signal analogique de l’image définit la densité d’information stockée pour une image vidéo analogique et ainsi sa qualité optique. Celle-ci dépend du rapport largeur/hauteur, du rythme de transmission des images et du nombre de lignes de l’image. Toutes ces caractéristiques sont des facteurs de qualité de l’image animée. La largeur de bande est indiquée en hertz (Hz unité de mesure de la fréquence). Le standard de télévision européen PAL (acronyme pour Phase Alternating Line) définit une image avec un rapport largeur/hauteur de 4:3, 576 lignes affichées (le nombre total de lignes est de 625) et un rythme de transmission de 25 images par seconde. Ceci exige une largeur de bande d’environ 5 MHz (mégahertz). Dans une vidéo numérique, toutes les caractéristiques susmentionnées de l’image sont converties en séries de valeurs binaires (des 0 et des 1). À la largeur de bande d’une image analogique correspond dans la vidéo numérique le nombre de bits par seconde ou débit binaire. Dans le langage courant, l’expression «largeur de bande» continue à être utilisée, bien que l’unité de mesure soit complètement différente.
Compression analogique et sous-échantillonnage 4:2:2
Un bref rappel historique est nécessaire pour expliquer la compression analogique. Lorsque la restitution analogique commerciale d’images vidéo en était à ses débuts, la norme CCIR (recommandation du Comité Consultatif International des Radiocommunications de l’Union internationale des télécommunications) était utilisée en Europe. Elle définissait l’image vidéo comme monochrome, d’un format 4 :3; la trame de l’image comportant 576 lignes affichées, et le rythme de transmission étant de 25 images par seconde. Les appareils de télévision noir et blanc furent produits en Europe conformément à cette norme CCIR. Un problème se posa lors de l’introduction de la télévision couleur : trois canaux étaient nécessaires pour représenter une image couleur, respectivement pour le rouge, le vert et le bleu (R, V, B. RVB ou RGB, de l’anglais Red, Green, Blue. Le codage RVB indiquerait l’intensité de chacune de ces trois couleurs primaires.) L’image couleur nécessitait donc une largeur de bande trois fois plus grande que celle de l’image noir et blanc. Le standard fondé sur les trois canaux couleur avec 576 lignes affichées et un débit de 25 images par seconde s’est appelé PAL. Les téléviseurs noir et blanc ne pouvaient gérer ainsi qu’un seul canal, ce qui ne correspondait pas à une image en noir et blanc où les tons gris seraient correctement représentés, puisqu’une seule sélection couleur au maximum serait visible. Une astuce technique permit de résoudre ce problème. On calcula trois nouveaux canaux à partir des trois canaux R, V et B: un canal contenait l’image noir et blanc, qui correspond à l’information sur la luminosité de chaque pixel (information de luminance). Les deux autres canaux contenaient des signaux dits de chrominance différence bleu ou rouge, qui représentent les informations couleur :
R, V, B → Y, PB , PR / Y, CB, CR
R = canal rouge
V = canal vert
B = canal bleu
Y = informations de luminance = image noir et blanc
PB signal de chrominance différence bleu (B - Y) (analogique)
CB signal de chrominance différence bleu (B - Y) (numérique)
PR signal de chrominance différence rouge (R - Y) (analogique)
CR signal de chrominance différence rouge (R - Y) (numérique)
Y, PB et PR contiennent, exactement comme R, V et B, toute l’information relative à l’image. Les informations contenues dans Y, PB et PR permettent de restituer les canaux rouge, vert et bleu. On appelle R, V, B, ainsi qu’Y, PB et PR les signaux des composantes («component» en anglais). Les télévisions noir et blanc ne représentent que le canal Y, l’information sur la couleur est ignorée. Ill. 1 montre la décomposition de l’information sur la couleur dans trois canaux monochromes:
Les codages RVB et Y′CBCR sont deux procédés différents de décomposition de l’information couleur d’une image en trois canaux. La combinaison des informations de chacun des trois canaux donne dans les deux cas le même contenu informationnel (voir l’image source en couleur dans ill. 1). Différents standards Y′CBCR existent, dont la variante SDTV est représentée ici.
La représentation en couleur des canaux doit être interprétée comme une aide à la compréhension. Tous les canaux sont en effet composés d’un signal monochrome, qui pourrait être représenté par une image noir et blanc, dont le contenu informationnel serait identique. Les composantes CB et CR du signal Y′CBCR sont des signaux de transport de l’information couleur de l’image et ne sont en réalité jamais représentés. Ils génèrent les composantes RVB qui seront, elles, représentées. Le canal de luminance Y′ correspond à l’image émise par un téléviseur noir et blanc en train de réceptionner l’image couleur Y′CBCR.
Les barres de couleur RVB visibles sur la partie droite de l’image source présentent les valeurs 255, 0, 0 pour le rouge, respectivement 0, 255, 0 pour le vert et 0, 0, 255 pour le bleu, dans l’espace chromatique RGB (3 × 8 bits). Les valeurs de gris des trois couleurs primaires ne sont pas identiques dans la représentation du canal de luminance Y′, c’est-à-dire que les couleurs de base rouge, vert et bleu sont pondérées différemment lors de la conversion RVB à Y′CBCR. Cette pondération résulte de la combinaison de différents facteurs techniques issus du développement historique du téléviseur couleur. Il a été tenu compte, pendant l’étape de transformation, de la façon dont l’oeil humain perçoit la luminosité couleur.

Cette astuce technique a permis d’utiliser en même temps des appareils de télévision noir et blanc et couleur mais n’a pas permis de diminuer la largeur de bande nécessitée par le signal des composantes en comparaison avec le signal noir et blanc. Par la réduction de la largeur de bande de chacun des trois canaux, i.e. une perte d’information, le signal des composantes a pu être réduit à un seul canal. Cette compression analogique a donné naissance au signal appelé «composite». Ill. 2 explique les prises des signaux vidéo analogiques Component (Y′, PB, PR), S-video (Y′, C) et Composite («vidéo»). L’Illustration montre les formes typiques de prises Component, S-Video et Composite sur les appareils. Il existe de même des formats vidéo analogiques où le signal est émorisé sur une bande magnétique comme signal Component, S-Video ou comme signal Composite.

Selon le type d’exploitation des images qu’on retient, on choisira de conserver toute l’information ou de réduire la largeur de bande. C’est pourquoi différents standards ont été développés, qui réduisent plus ou moins fortement la largeur de bande du signal, pris comme un tout: par ex. avec la réduction de trois canaux (component) à deux (S-Video) ou à un seul canal (composite). De même, on a employé des astuces techniques pour pouvoir conserver une image aussi nette que possible même avec une réduction des données. En partant du signal «Y′, PB et PR» les deux composantes de couleur sont réduites à un seul canal commun, où la moitié de la largeur de bande initiale reste disponible pour chacune d’elles (Y′, C). Ce procédé a été à la base de la compression numérique fondée sur une structure d’échantillonnage 4:2:2 : un canal avec une densité d’information complète et deux canaux de densité réduite de moitié (les deux composantes de chrominance sont échantillonnées à la moitié de la fréquence d’échantillonnage de luminance). Comme l’information de luminance Y′ reste disponible avec une résolution complète, et que seules les informations de couleur rouge et bleu sont réduites, l’impression de netteté de l’image recomposée est préservée. On parle alors de réduction de format 4:2:2 de la largeur de bande, respectivement de sous-échantillonnage de la chrominance.
Ill. 3 présente la réduction des données obtenue par une division sélective de la résolution horizontale des signaux de différence de couleur PB, PR , qui définissent la proportion d’image en couleur bleue, respectivement rouge. Les représentations des canaux U et V montrent déjà que leur contribution à la netteté de l’image est peu importante et que la perte de 50% de l’information contenue dans l’image par canal a un impact faible sur l’impression de netteté de l’image recombinée.
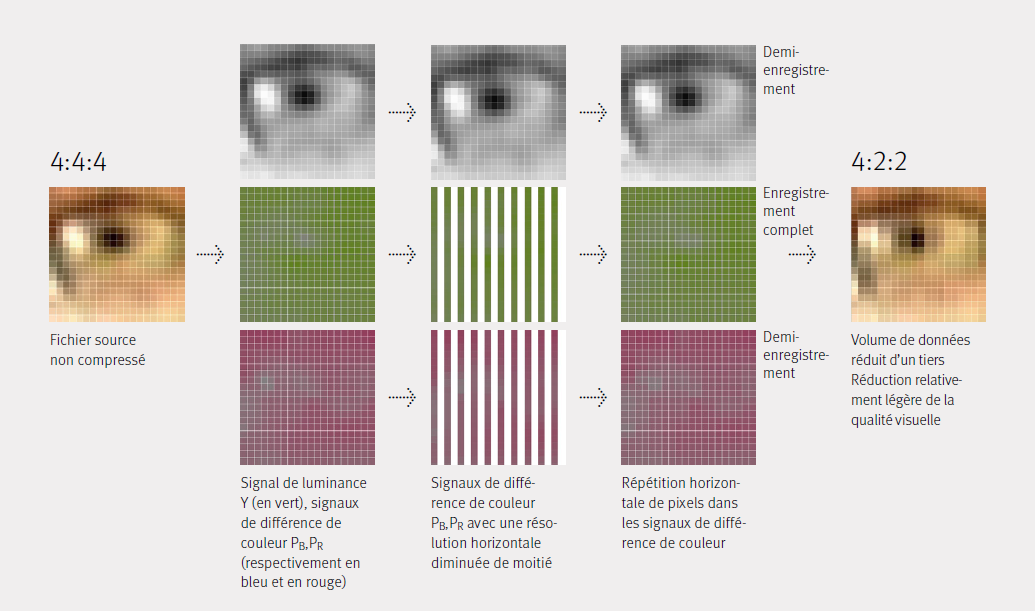
Comme l’image analogique PAL contient par définition 576 lignes actives, la réduction de moitié de la largeur de bande entraîne une diminution de moitié de la résolution horizontale des canaux rouge et bleu. Le canal vert peut être reconstruit avec une résolution complète à partir du signal de luminance. Les différentes options usuelles du sous-échantillonnage de la chrominance pour les images numériques sont décrites en termes similaires (4:2:0, 4:1:1, etc.). On trouvera chez Poynton (2002) une explication détaillée de la nomenclature.
Si un signal est numérisé sans compression après réduction de la largeur de bande, le résultat est certes numériquement non compressé, mais du fait de la réduction déjà survenue à l’état analogique, la qualité du signal est naturellement inférieure à celle issue d’une numérisation opérée à partir de R, V, B ou Y′, PB et PR.
La construction de l’image vidéo numérique fondée sur des pixels s’oppose à la représentation ligne par ligne d’une vidéo analogique. Lors de la numérisation d’une vidéo analogique au moyen d’un convertisseur A/D, la résolution verticale numérique est indiquée de façon univoque par le nombre de lignes. La résolution horizontale de chaque ligne reste cependant à déterminer par les mêmes procédés que pour d’autres images analogiques, tels les films: le signal analogique continu, qui peut prendre n’importe quelle valeur entre deux bornes, devient un signal avec certaines valeurs quantifiées discrètes. Il est donc nécessaire de définir une fréquence d’échantillonnage et de procéder à une quantification.
Si une représentation avec des pixels carrés s’impose, la résolution horizontale se calcule au moyen du nombre de lignes et du rapport largeur/hauteur des pixels. On obtient pour un signal vidéo PAL une valeur de 768 pixels horizontaux. La résolution de 768×576 (4:3) est certes encore utilisée actuellement mais le signal numérique PAL usuel est indiqué avec une résolution de 720×576 (5:4) et des pixels rectangulaires («non square» en anglais).
Codec, conteneur et compression
Le terme ‹codec› est l’acronyme anglais pour ‹coder and decoder›. L’encodage est la traduction d’une information analogique en un code numérique, par un convertisseur A/D et éventuellement par un compresseur (i. e. un encodeur, constitué d’un convertisseur A/D et d’un compresseur). Le décodage nécessite un décodeur. En présence de données compressées, un expanseur est nécessaire. Un fichier numérique peut, lui aussi, être traité par un encodeur si, par exemple, le signal vidéo a été numérisé sans compression ou déjà généré numériquement mais qu’un fichier MPEG doit être créé pour un DVD. Dans ce cas, on parle de transcodage.
Un codec est une instruction de codage ou de décodage de données dans le but de réduire le volume du stream ou du fichier, sans perte ou avec perte. Des codecs spécifiques existeront pour l’image, le son et pour les sous-titres.
Il existe des codecs très différents pour les images animées, selon les besoins d’utilisation de ces dernières (enregistrement, montage, diffusion en ligne dite streaming, archivage, etc.). En effet, les besoins – et le matériel qui y répond – dépendent du cycle de vie d’une vidéo. De nombreuses variantes, de qualité variable, et différentes versions des codecs existent également pour ces mêmes raisons. Différents facteurs, tels que l’espace mémoire, la vitesse de transmission des données et de leur traitement, l’infrastructure disponible et les coûts afférents rendent généralement impossible l’obtention d’une qualité maximale à toutes les étapes du cycle de vie.
La coexistence de divers codecs et formats de données sert aussi les intérêts de l’industrie à détenir des formats propriétaires qui lui assurent un contrôle commercial et une clientèle dépendante.
La compression sans perte («lossless compression» en anglais) qualifie la compression où le fichier compressé qui en résulte est idéalement plus petit que le fichier source mais où l’information est restée identique après le codage, étant simplement codée autrement.

Si des données ont été éliminées lors du codage ou transcodage, il s’agit d’une compression avec perte («lossy compression» en anglais). La compression est souvent imperceptible ou difficilement décelable à l’oeil nu, bien qu’une réduction massive d’information ait pu être effectuée au niveau des données lors de la compression. La «visually lossless compression» n’est pas définie, elle repose sur la perception subjective. C’est pourquoi ce type de compression n’est pas approprié pour des copies destinées à l’archivage à long terme. Tout au plus se prête-t-il à des copies d’utilisation.
Pratiquement tous les codecs ont un algorithme de compression à la base. Les algorithmes peuvent se différencier fortement les uns des autres : il existe ainsi des procédés pour compresser les images elles-mêmes (compression Intraframe) et certains qui compressent une séquence d’images (compression Interframe). L’ill. 5 explique la compression spatiale : dans l’exemple représenté, un jeu de données de 6 × 6 pixels avec quatre valeurs de gris différentes est divisé en 2 × 2 jeux de données. Les valeurs de gris de ces jeux de données sont uniformisées par calcul, ce qui permet de former un jeu de données 3 × 3 qui présente la moitié de la résolution horizontale et verticale initiale. La compression spatiale ne réduit pas l’information de l’image de manière uniforme sur toute la surface de l’image, mais en fonction de la densité d’information des parties de l’image d’intensité différente. Les zones de l’image présentant une densité d’information élevée sont moins compressées que celles contenant peu d’informations sur l’image (par ex. le ciel bleu).
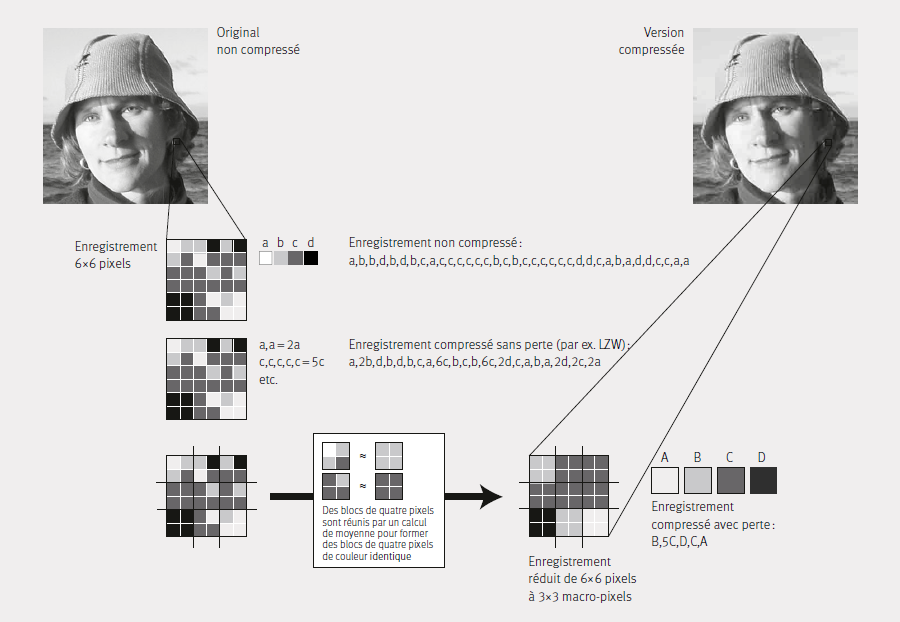
Selon le type de codec, il est possible d’ajuster le taux de compression ou le débit des données, c’est pourquoi la mention du codec employé ne permet pas d’en déduire sans autre le type et l’intensité de la compression utilisée, qui doit donc être mentionnée explicitement. La palette de codecs est continuellement élargie pour augmenter leur efficience et les adapter à de nouveaux usages ; cette réalité explique aussi le risque d’obsolescence, lequel importe dans l’archivage à long terme et concerne justement les fichiers.
Le conteneur enregistre les données codées par le codec et opère ainsi la liaison entre l’image, le son et d’autres informations. Le conteneur est, entre autres, responsable de la transmission synchrone au player des données image et son. Il coordonne donc le travail des codecs vidéo et audio. Les conteneurs contiennent entre autres les éléments suivants :
-
codec et données vidéo
-
codec et données audio
-
codec et données des sous-titres
Format
Le terme de format est souvent employé de façon imprécise et pour différentes choses dans le domaine des médias. Pour éviter toute confusion et tout malentendu, nous définissons ici quelques notions.
Format des médias
De nos jours, tous les moyens techniques de communication de masse entre les êtres humains sont généralement désignés comme médias, qu’il s’agisse de la radio, de la presse, d’internet, etc. Dans le domaine audiovisuel, on entend par <média> la forme technique du moyen de communication. Exemples : vidéo, film, fichier.
Format vidéo
Le format vidéo est un terme générique. Il désigne d’une part les différents supports de données – cassettes, bobines ouvertes – avec leurs spécificités propres, et est d’autre part aussi employé pour désigner des fichiers. Ces derniers sont décrits plus précisément au moyen des termes <conteneur> et Codecs.
Les dimensions et normes techniques suivantes définissent un format vidéo :
type de moyen de stockage : cassette, bobine ouverte, disque, etc. ;
type de procédé de stockage : optique, magnétique, magnéto- optique ;
type d’enregistrement, signal spécifique (par ex. U-matic Low Band vs. Hig Band, DVCAM vs. DV ;
fréquence d’images et échantillonnage (nombre d’images par seconde, en anglais «Frames per Second», fps ; balayage entrelacé ou progressif) ;
dimensions de l’image et rapport largeur / hauteur ( Standard Definition SD vs. High Definition HD). Exemples: Betacam SP PAL, HDV 1080i ou HDV 720p
Format d’image (= rapport largeur/hauteur)
Le format d’image décrit : (1) le rapport largeur/hauteur d’une image, soit par exemple : 16:9, 4:3 pour la vidéo ou 1,37:1 et 1,66:1 pour le film etc. ; et (2) le type de projection optique de l’image, soit la projection d’une image sphérique ou anamorphosée (ayant subi une deformation reversible).
Nous utiliserons dans la suite du document l’expression «rapport largeur/hauteur».
Le rapport largeur/hauteur diffère selon les médias audiovisuels. Le transfert d’un média audiovisuel à un autre média (par exemple le transfert du film à la vidéo) peut entraîner un transfert dans un autre rapport largeur/hauteur. L’exemple le plus courant de cette transformation, est le transfert d’une image d’un format vidéo de rapport 4:3 à un format de rapport 16:9. Le transfert peut s’opérer de différentes manières :
-
transfert direct (= Curtains, Pillar / Letter Box, avec ou sans un reflet flou)
-
agrandissement et rognage (suppression de la partie supérieure et inférieure de l’image, en anglais «cropping»)
-
pan & scan («pivoter et découper», recadrage avec suppression variable)
-
distorsion (perte des proportions correctes)
Chacune de ces solutions présente des avantages et désavantages. Le choix du bon procédé exige d’être bien informé et de tenir compte de l’utilisation concrète. Ni le hasard ni un manque de connaissances ne doivent être les principaux facteurs décisionnels.
La conservation du rapport largeur/hauteur et la transmission complète de l’information de l’image sont indispensables à la conservation, de sorte que seule l’intégration au format 16:9 (ainsi que la conservation du rapport largeur/ hauteur dans le master de conservation) convient aux originaux de rapport 4:3. La surface totale de l’image reste ainsi conservée avec un rapport largeur/hauteur correct pour des utilisations futures (voir ills. no 6+7).
Ill. 7 compare les standards 2K, DCP 2K et Full HD de l’utilisation des surfaces des films d’un rapport 4:3 et 16:9. Les techniques du film et de la vidéo ont engendré une multitude de formats. La flexibilité de la représentation numérique des images a encore élargi les possibilités et donc le nombre de standards. Le fait que le cinéma et la télévision aient évolué ces trente dernières années du rapport 4:3 au rapport 16:9 se répercute sur les standards vidéo courants de Standard Definition (SD) et d’High Definition HD ainsi que sur leur résolution en pixels. Le rapport de largeur/hauteur en pixels ne concorde souvent plus avec le rapport largeur/hauteur de la représentation. Le chapitre suivant donne plus d’informations à ce sujet.
Dans la technique cinématographique, l’arrivée de la numérisation a entraîné une définition des standards 2K et 4K pour l’image numérisée de film. 2K et 4K se rapportent à la surface maximale entre les perforations d’une image de film 35 mm et indiquent 2056 voire environ 4112 pixels horizontaux. Le film classique de 35 mm, qui s’étend sur 4 perforations, a un rapport de 4:3, d’où la surface de 2056×1536 pixels pour le standard 2K et de 4112×3072 pour 4K. Les standards de projection numériques modernes pour le cinéma sont appelés 2K DCP et 4K DCP mais se rapportent à une image dont le rapport est presque celui du 16:9. Elles mesurent 2056×1080 pixels pour 2K et 4112×2160 pour 4K. Ceci peut créer des confusions car les deux options 2K et 4K ne sont pas optimisées pour le même rapport largeur/hauteur. L’illustration 6 montre la problématique en détail.


Si une image est transférée dans un format de rapport plus large sans coupure ni rognage, des bandes noires sont engendrées à gauche et à droite (Pillar Box, Curtains). Lors d’un transfert dans un format de rapport moins large (Letterbox), les bandes noirs apparaissent en haut et en bas.
Optique sphérique
Une optique sphérique crée une image sphérique qui n’a pas subi de déformation, au contraire de l’optique anamorphique. Les optiques sphériques tirent leur nom de la forme de leurs deux surfaces qui correspond à la découpe d’une boule (du grec ≪sphaira≫ = balle, boule, sphere (céleste)), ce qui lui confère, entre autres caractéristiques, une symétrie rotationnelle.
Des aberrations, et particulièrement l’aberration dite sphérique, se produisent lors de l’utilisation d’objectifs sphériques et peuvent être corrigées dans les objectifs modernes par de légères modifications de la forme de leur surface. Les objectifs ainsi corrigés sont appelés asphériques. Contrairement aux objectifs anamorphoseurs, les objectifs asphériques ont une forme qui ne varie que très légèrement de la forme de la surface sphérique.
La copie d’un film cinéma est souvent désignée en anglais par l’expression «Spherical 35 mm Print », ce qui signifie que les copies peuvent être projetées correctement sans recourir à des objectifs anamorphoseurs. La «Spherical Print» d’un film en CinemaScope est coupée horizontalement, dans un rapport largeur/hauteur de 4:3 ou de 16:9 («format large», dit «Widescreen») lors de la projection, ou en mode «boîte à lettres («Letterbox»), avec une image dont la surface est moindre.
Optique anamorphique
Le vocable «anamorphique» tire son origine de la racine verbale grecque «transformer». Il désigne en optique les objectifs qui déforment l’image d’un objet.
La technique cinématographique classique recourt principalement aux objectifs anamorphoseurs, qui écrasent ou étirent l’image dans un sens donné. C’est ainsi que les images larges de format CinemaScope, filmées sur des pellicules 35 mm et projetées avec le rapport largeur/hauteur prévu, seront d’excellente qualité lors de leur projection (cf. illustration no 8).
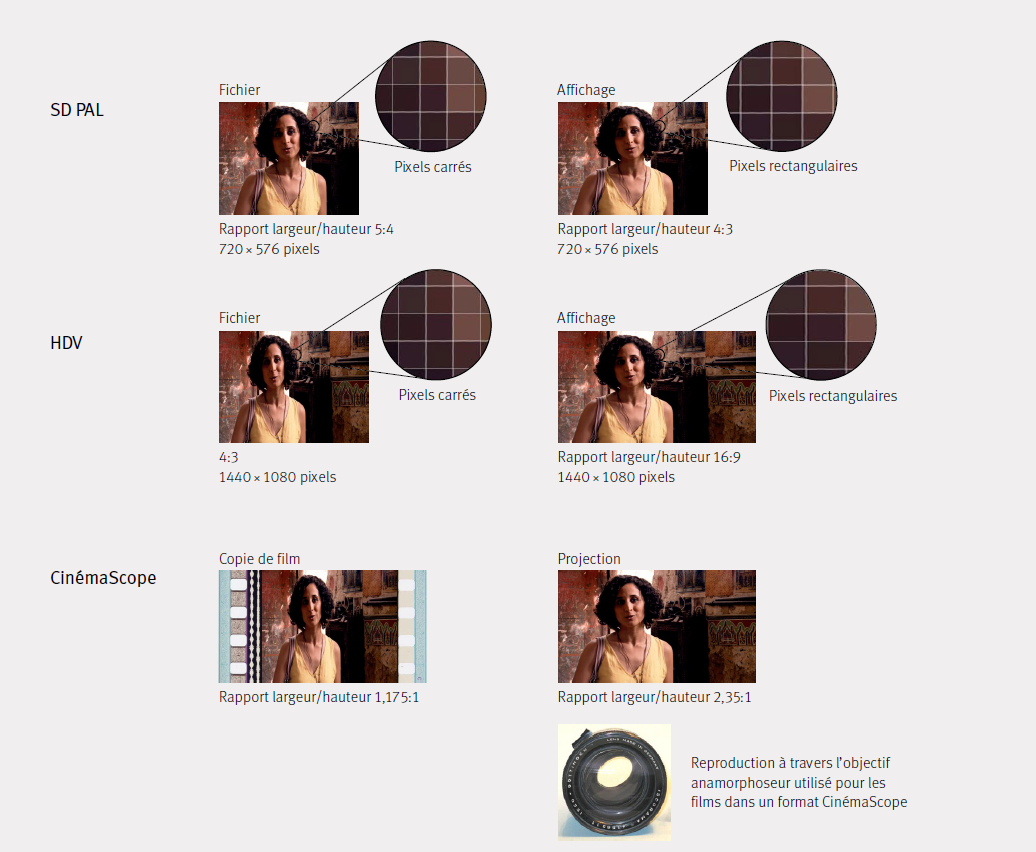
Le film 35 mm avec une piste sonore optique est conçu pour une dimension maximale d’image de 21,9 mm de large et de 18,6 mm de hauteur lors de la projection, ce qui correspond à un rapport largeur/hauteur de 1,18:1. L’image CinemaScope peut être produite avec un rapport largeur/ hauteur de 2,35:1 en recourant lors de l’enregistrement à une optique qui écrase horizontalement l’image dans un rapport 2:1 lors de la prise de vue et l’étire horizontalement dans un rapport 1:2 lors de la projection. La projection non déformée d’une image au rapport 2,35:1 causerait une très mauvaise utilisation de la surface du film (mode boîte à lettres).
La stratégie décrite ci-dessus a été reprise pour l’enregistrement des images animées. Le rapport largeur/hauteur des capteurs de la caméra ne correspond souvent pas aux exigences changeantes sur le rapport largeur/hauteur du format de publication ; les caméras doivent pouvoir enregistrer différents rapports largeur/hauteur. Il a donc fallu développer plusieurs solutions qui recourent aussi bien à l’emploi d’objectifs anamorphoseurs qu’à la déformation et à la correction des images grâce au procédé numérique du changement d’échelle. Les images numériques qui sont stockées dans un rapport largeur/hauteur différent du rapport dans lequel elles sont représentées, sont aussi désignées comme des pixels non carrés (voir sous-chapitre Pixels carrés (square) et pixels rectangulaires (non-square) ci-dessous).
Les vidéos stockées dans un rapport largeur/hauteur différent du rapport prévu pour leur diffusion voient habituellement ce rapport être corrigé par le software-player pendant la projection au moyen d’un changement d’échelle numérique pendant . Le player doit pour ce faire disposer des métadonnées relatives au rapport largeur/hauteur prévu pour la projection. Ces informations peuvent être enregistrées dans l’en-tête du fichier (header) ou dans les métadonnées du Container. Il arrive que ces informations ne concordent pas; dans ce cas, les players, selon le type de logiciel, utiliseront ou traiteront prioritairement l’une ou l’autre des deux informations.
Pixels carrés (square) et pixels rectangulaires (non-square)
Les pixels (de l’anglais «picture element») sont en principe des éléments carrés («square») constitutifs d’une image numérique. Chaque pixel a une valeur colorimétrique ou une échelle de gris. Le rapport largeur/hauteur d’une image représentée au moyen de pixels se calcule sur la base de la totalité des pixels en largeur et de la totalité des pixels en hauteur, divisés par le plus grand commun dénominateur des deux nombres.
Par ex. : «Full HD», largeur : 1920 pixels,
hauteur : 1080 pixels
= 1920/120:1080/120
= 16:9
Certains formats vidéo, lorsqu’ils sont enregistrés sous forme de fichier, ne conservent cependant pas le rapport largeur/hauteur de pixels dans lequel ils sont représentés.
Par ex. : SD PAL, largeur : 720 pixels, hauteur : 576 pixels
= 720/144:576/144
= 5:4
Le rapport largeur/hauteur de représentation est 4:3.
Dans ce cas, on parle de pixels rectangulaires («nonsquare »), car la représentation doit étaler les pixels horizontalement, pour passer du format 5:4 à la représentation de rapport 4:3. L’étendue de l’allongement est dans le cas du SD PAL de 6,66 %. La densité d’information stockée dans l’image reste la même, les pixels ne sont cependant carrés, mais rectangulaires.
Si ce type de représentation est utilisé pour le SD PAL, c’est que ce dernier trouve son origine dans la technique vidéo classique. Pour les formats vidéo HD, c’est une autre façon d’économiser de l’information, soit une forme de compression.
Tous les projecteurs et moniteurs d’usage courant aujourd’hui représentent en principe toujours les images
numériques au moyen de pixels rectangulaires. Si le fichier contient des pixels carrés, la carte graphique devra les convertir.
Format de fichier
Le format de fichier est le code numérique, dans lequel l’information contenue est enregistrée. La connaissance du format de fichier est essentielle pour l’interprétation de l’information stockée dans un fichier. Les contenus des fichiers numériques ne se laissent pas identifier par une simple consultation des données. Il faut ainsi toujours une aide à la traduction pour prendre connaissance du contenu. Sans cette identification (il peut s’agir d’une simple terminaison de fichier comme par ex. <.dv>, <.bmp>) et sans l’infrastructure appropriée, l’information n’est qu’une masse inutile de nombres binaires. Les systèmes d’exploitation modernes associent au moyen de ces formats les fichiers à des applications qui peuvent les interpréter. Il existe des formats de fichiers qui peuvent englober divers types de fichiers. Ces formats sont appelés formats conteneurs ou Wrapper. Dans le domaine audiovisuel, les conteneurs peuvent comprendre différents codecs et flux audio et vidéo.
Il existe des formats de fichiers qui peuvent englober divers types de fichiers. Ces formats sont appelés formats conteneurs (ou Wrapper). Dans le domaine audiovisuel, les conteneurs peuvent comprendre différents codecs (voir sous-chapitre Codec, Container et compression ci-dessus) et flux (voir sous-chapitre Stream ci-dessous), c’est-à-dire des images et du son dans différents codecs ainsi que des informations supplémentaires comme les codes de synchronisation temporelle (Timecodes), les sous-titres et les métadonnées, selon le type et la flexibilité du container.
Il est rare de rencontrer des formats de fichiers purs, à l’exemple d’un .AIFF (voir glossaire) ou d’un .DV. Il s’agit le plus souvent d’un format conteneur comme par exemple un fichier audio PCM dans un Wave-Container avec la terminaison .wav/WAV ou d’un fichier vidéo avec un codec DV dans un QuickTime- Movie-Container avec la terminaison .mov/MOV. Les formats conteneurs sont utilisés dans le but de pouvoir stocker divers éléments (par exemple divers codecs, images fixes, Timecodes) dans un seul fichier, pour rendre possibles des représentations multimédias. L’archivage exige aussi le stockage de fichiers numériques annexes, par exemple la sauvegarde dans un container des fichiers textes contenant les métadonnées avec les fichiers image et son. Le conteneur MXF offrira cette possibilité mais ce n’est de loin pas le cas de tous les formats de conteneur.
En règle générale, il faut savoir que les conteneurs, comme les codecs, doivent être sélectionnés avec soin pour bien fonctionner avec l’infrastructure à disposition ou qui sera prévue (systèmes d’exploitation, logiciels de lecture et de traitement, etc.). Le QuickTime-Player n’est ainsi plus soutenu depuis 2016 sur les systèmes d’exploitation Windows, ce qui nécessite de passer à d’autres logiciels de lecture (software-player) pour assurer la restitution de vidéos issues des conteneurs QuickTime-Movie (MOV). Or, le cas échéant, ces logiciels ne soutiendront pas tous, les fonctionnalités originelles prévues pour la lecture des vidéos. Passer d’un conteneur à un autre exige également, au même titre que les transcodages (voir sous-chapitre Codecs et transcodages dans le chapitre Numérisation de vidéo), un très bon contrôle car le risque reste permanent que d’importantes métadonnées (par exemple le rapport largeur/hauteur ou l’espace chromatique), d’importants éléments (par exemple le Timecode) ou certaines caractéristiques (par exemple la fréquence des images) soient perdues dans le processus.
Les fonctionnalités spécifiques aux différents logiciels de lecture différent les unes des autres: par exemple, avance et retour de lecture, commande des images fixes, représentation du niveau sonore, du Timecode et autres options spéciales de représentation. Hormis les différences de fonctionnalités, la représentation peut aussi être différente en fonction de la combinaison choisie pour le software-player, le codec et le conteneur. Ill. 9 montre que les software-player offrent différentes priorisations des métadonnées, par exemple du codec vidéo, par rapport aux métadonnées du conteneur. Une conséquence en est, par exemple, la largeur de représentation différente pour un même et seul fichier.
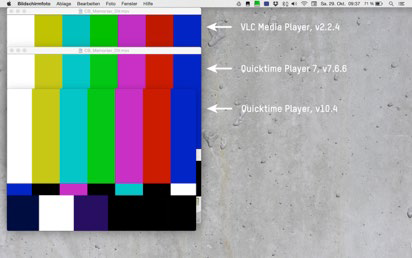
Ill. 10 montre une autre particularité essentielle, qui différencie ces logiciels de lecture les uns des autres: Les bibliothèques de codecs spécifiques auxquelles recourent les software-player. L’usage de telle ou telle bibliothèque de codecs expliquera les différences de couleur dans les représentations d’un fichier pourtant identique.

Format d’archivage, format d’utilisation
Le cycle de vie d’une oeuvre audiovisuelle peut se diviser grossièrement entre les secteurs d’activités suivants : enregistrement, post-production, distribution/exploitation et archivage. Une palette sur mesure de formats de fichiers existe pour chaque type d’activité. Ces formats peuvent être attribués aux secteurs d’activité comme suit :
Format d’enregistrement
Le format d’enregistrement est le format de fichier ou le format vidéo analogique, dans lequel les images sont enregistrées pendant le tournage ou la prise de vue vidéo. Il détermine le cadre maximal de la qualité de l’image et de l’esthétique.
Format de post-production
On l’appelle aussi format de traitement car il s’agit des formats de fichier dans lesquels la vidéo va être traitée (montage, réglage de la lumière, effets spéciaux etc.). La qualité du matériel originellement à disposition peut être amoindrie lors de la post-production si des programmes et des codecs sont inadéquats. Le maillon le plus faible de la chaîne détermine la qualité du produit final. Ne jamais diminuer la qualité du format d’enregistrement, à quelque étape du traitement, est le cas idéal. On parle de formats <mezzanine>, dans le contexte de l’archivage, pour les formats qui ne contiennent pas toute l’information mais néanmoins assez pour qu’on puisse la traiter (par ex. réglage de la lumière ou montage), sans que les défauts n’apparaissent sur l’image. Les formats <mezzanine> les plus courants sont par ex. Apple ProRes 422 HQ et ProRes 444 ou Avid DN×HD et DN×HD444.
Format d’utilisation
Il peut s’agir de divers formats de fichiers, généralement fortement compressés, qui ont été optimisés pour le visionnement dans un contexte particulier: commercialisation et projection dans des cinémas, diffusion à la télévision, projections publiques ou à domicile, consultation sur le web. La qualité peut varier, du niveau cinéma IMAX jusqu’à une qualité Youtube très modeste. Le format d’utilisation permet par ex. un visionnement à la bonne vitesse mais il ne peut pas être retravaillé ou alors avec une très mauvaise qualité; un nouveau réglage de la lumière (correction des couleurs) s’avère quasi impossible. De nombreux termes sont utilisés couramment selon le contexte: dans les cinémathèques, cinémas et musées, il sera question de format ou de copie de visionnement, de projection ou de distribution («dissemination copy»). Dans des services d’archives, on parlera de copie d’utilisation, de consultation ou de circulation, si tant est qu’on ne recourt pas au terme encore plus général de DIP (Dissemination Information Package) du modèle OAIS.
Format d’archivage
Le format d’archivage est le format dans lequel les vidéos, les films et les documents sonores sont sauvegardés et traités de façon à rester utilisables le plus longtemps possible. Le master de conservation ou master archivé, soit le fichier qui devra être durablement archivé et pris en charge par le service d’archives, sera enregistré dans un format d’archivage. Il devrait idéalement conserver la totalité de l’information qui a été produite pendant la numérisation. Mais comme les scanners de films engendrent des formats intermédiaires propriétaires, ceux-ci doivent être convertis dans un format normalisé. Pour le cinéma, on utilise à présent généralement l’espace chromatique RVB avec l’échantillonnage 4:4:4, tandis que pour la vidéo et la télévision, la règle est l’espace Y′CBCR, avec un échantillonnage 4:2:2. Il est important dans le format d’archivage de documenter avec précision l’emplacement du blanc dans l’espace chromatique.
Nota bene : les masters archivés ne sont pas destinés à la projection. Chaque visionnement/utilisation induit une usure du master respectivement contient le risque d’engendrer des erreurs ou des dommages suite à une manipulation incorrecte (pertes de données).
Dernières modifications: novembre 2019