In diesem Kapitel wird ausführlich auf Begriffe und ihre Bedeutung eingegangen, die für das Verständnis der Erhaltung von Video essenziell sind. Dazu gehören:
-
die Erklärung, wie Video farbig wurde und was unter Farbunterabtastung zu verstehen ist,
-
worin sich Codec und Container unterscheiden und weshalb Kompression im Videobereich wichtig ist,
-
die vielfältige Anwendung des Begriffs Format, z.B. das Bildformat (=Bildseitenverhältnis), dessen Verständnis auch für den Filmbereich essentiell ist,
-
wie gewisse Linsen in der analogen Welt bewegte Bilder dehnen oder stauchen (anamorphotisch) und weshalb Pixel deshalb in der digitalen Welt unterschiedliche Formen (square und non-square) haben können,
-
welche Formate im Lebenszyklus eines Videos vorkommen (vom Aufnahme- über das Archiv- zum Distributionsformat).
Gewisse Begriffe wie z. B. «Format» werden in der audiovisuellen Welt häufig unscharf verwendet; die nach wie vor relevante Unterscheidung von Film und Video verwischt sprachlich oft, vielleicht weil man sich umgangssprachlich nur auf den Inhalt und das Genre bezieht, wogegen bei Erhaltungsfragen die (technische) Form essenziell ist. Um die hier behandelten komplexen technischen Gegebenheiten und Herausforderungen der digitalen Erhaltung klar zu beschreiben, muss die dafür verwendete Sprache sehr präzis sein. Im Folgenden werden einige der wichtigsten Begriffe erläutert.
Videokassette
Eine Videokassette ist ein Magnetband in einer Kunststoffkassette mit einer Aufwickel- und einer Abwickelspule, die das Abspielen in einem spezifischen Abspielgerät ermöglicht. Das Band kann entsprechend den Formatspezifikationen unterschiedliche Länge, Breite und Dicke haben sowie unterschiedliche magnetische Eigenschaften (sog. Koerzitivkraft). Das Band ist auf das Videosignal eines bestimmten Videoformats ausgerichtet.
Videoplayer/-recorder
Ursprünglich Abspiel- bzw. Aufnahmegerät, heute auch Computer-Programm (z. B. ein sog. Software-Player), das ein digitales Videosignal aufzeichnen oder aus einer Datei auf dem Computermonitor bzw. einem Projektor wiedergegeben werden kann. Ein analoges Signal muss zuerst mit einem geeigneten A/D-Wandler konvertiert bzw. digitalisiert werden, damit es von einem geeigneten Programm verarbeitet werden kann.
Analoge und digitale Aufzeichnung
Bei der analogen Aufzeichnung von Videobildern wird das Bildsignal in Zeilen aufgeteilt und Zeile um Zeile z. B. auf ein Magnetband geschrieben. Beim Abspielen wird das Bildsignal entsprechend zeilenweise wiedergegeben. Um Bildflimmern zu vermeiden, werden zudem zwei Halbbilder aufgezeichnet, welche nacheinander übertragen bzw. ausgelesen werden und jeweils nur jede zweite Bildzeile enthalten. Die Unterschiede in der Bildinformation werden in diesem Fall als Unterschied in der Intensität der Magnetisierung aufgezeichnet.
Bandbreite/Datenrate des Videobildsignals
Die Bandbreite eines analogen Bildsignals definiert die Informationsdichte eines analogen Videobildes und somit dessen optische Qualität. Sie ist abhängig von Faktoren wie dem Seitenverhältnis, der Bildwiederholrate und der Zeilenzahl des Bildes, alles Qualitätsfaktoren des bewegten Bildes. Die Bandbreite wird in Hertz angegeben. Der europäische Fernsehstandard PAL definiert ein Bild im 4:3-Seitenverhältnis mit 576 sichtbaren Zeilen und einer Wiederholrate von 25 Bildern pro Sekunde. Dafür wird eine Bandbreite von ca. 5 MHz benötigt. Beim digitalen Video werden alle erwähnten Bildeigenschaften in Serien von binären Zahlen umgesetzt («Nullen und Einsen»). Die Entsprechung der Bandbreite eines analogen Bildes beim digitalen Video ist der Durchsatz an Bits pro Sekunde, die Datenrate. Umgangssprachlich ist weiterhin von Bandbreite die Rede, obwohl die Masseinheit komplett unterschiedlich ist.
Analoge Kompression, Video in Farbe, Farbunterabtastung 4:2:2
Die Erklärung der analogen Kompression erfordert einen kleinen historischen Rückblick. Am Anfang der kommerziellen analogen Wiedergabe von Videobildern in Europa steht der CCIR-Standard. Er definiert ein monochromes Videobild mit dem Seitenverhältnis von 4:3, das aus 576 sichtbaren Zeilen aufgebaut und mit einer Wiederholrate von 25 Bildern pro Sekunde wiedergegeben wird. Schwarzweissfernsehgeräte wurden in Europa diesem Standard entsprechend produziert. Bei der Einführung des Farbfernsehens stellte sich das Problem, dass für die Darstellung eines Farbbildes drei Kanäle für Rot, Grün und Blau (R, G, B) notwendig wurden. Das Farbbild benötigt die dreifache Bandbreite des Schwarzweissbildes. Der Standard, der auf drei Farbkanälen mit 576 Zeilen und einer Wiederholrate von 25 Bildern pro Sekunde aufbaut, heisst PAL. Entsprechend kann auf alten Schwarzweissgeräten maximal ein Kanal abgebildet werden. Dies würde nicht einem Schwarzweissbild mit einer korrekten Verteilung der Grautöne entsprechen, da nur maximal ein Farbauszug zu sehen wäre. Mittels eines technischen Tricks konnte dieses Problem jedoch gelöst werden. Aus den drei Kanälen R, G und B wurden drei neue Kanäle berechnet: Ein Kanal enthält das Schwarzweissbild, was der Information über die Helligkeit der einzelnen Bildpunkte entspricht (Luma oder Luminanz). Die anderen beiden Kanäle enthalten sogenannte Differenzsignale, welche die Farbinformationen darstellen:
-
R, G, B → Y, PB, PR
-
R = Roter Kanal
-
G = Grüner Kanal
-
B = Blauer Kanal
-
Y = Luma (Helligkeitsinformation) = Schwarzweissbild
-
PB = Blaues Differenzsignal (B - Y)
-
PR = Rotes Differenzsignal (R - Y)
Y, PB und PR enthalten genauso wie R, G und B die volle Bildinformation. Aus den Informationen, die Y, PB und PR enthalten, kann man den roten, den grünen und den blauen Kanal zurückgewinnen. Man nennt R, G, B sowie Y, PB, PR Komponentensignale (engl. «component»). Schwarzweissfernsehgeräte stellen nur den Y-Kanal dar, die Farbinformation wird ignoriert. Abb. 1 zeigt, wie die Teilung der Farbinformation in drei monochrome Farbkanäle funktioniert:
RGB und Y′CBCR sind zwei verschiedene Arten der Aufteilung der Farbinformation eines Bildes in drei Kanäle. Der kombinierte Informationsgehalt der drei Kanäle ist in beiden Fällen derselbe (das Ausgangsbild oben). Es gibt verschiedene Y′CBCR Standards. Hier dargestellt ist die SDTV Variante.
Die Darstellung der Farbkanäle in Farbe ist eine Verständnishilfe. Alle Kanäle bestehen tatsächlich aus einem monochromen Signal, das als Schwarzweissbild dargestellt werden könnte und dabei nicht weniger Bildinformation enthalten würde. Die CB und CR Komponenten des Y′CBCR Signals sind Transportsignale mit der Farbinformation des Bildes, sie werden in Realität nie dargestellt. Aus ihnen werden die RGB Komponenten generiert, die dann dargestellt werden. Der Luminanzkanal Y' entspricht dem Bild, das auf einem Schwarzweissfernseher zu sehen ist, wenn er das Y′CBCR -Farbbild empfängt.
Die RGB Farbbalken auf der rechten Seite des Ausgangsbildes haben im 8 bit RGB Farbraum die Werte 255, 0, 0 für Rot, 0, 255, 0 für Grün und 0, 0, 255 für Blau. In der Darstellung des Luminanzkanals Y' sind die Helligkeitsgrauwerte der drei Grundfarben nicht identisch, d. h. die Grundfarben Rot, Grün und Blau werden in der Konversion RGB zu Y′CBCR unterschiedlich gewichtet. Diese Gewichtung ist das Resultat von technischen Faktoren aus der Zeit der Entwicklung des Farbfernsehens. Bei der Transformation wurde darauf Rücksicht genommen, wie die menschliche Wahrnehmung in Bezug auf Farbhelligkeit funktioniert.

Dieser technische Trick ermöglichte die gleichzeitige Verwendung von Schwarzweiss- und Farbfernsehgeräten, aber es ergibt sich daraus keine Verkleinerung der benötigten Bandbreite des Komponentensignals im Vergleich zum schwarzweissen Signal. Durch Reduktion der Bandbreite jedes der drei Kanäle kann ein Komponentensignal auf einen einzigen Kanal reduziert werden. Dies entspricht einer analogen Kompression und das resultierende Signal wird «composite» genannt. Die Reduktion der Bandbreite bedeutet immer einen Verlust an Information. Abb. 2 erklärt die Anschlüsse für die analogen Videosignale Component (Y, PB, PR), S-Video (Y/C) und Composite («Video»). Zu sehen sind die typischen Erscheinungsformen von Component-, S-Video- und Composite-Anschlüssen an Geräten. Entsprechend gibt es analoge Videoformate, bei denen das Signal entweder als Component-, S-Video- oder als Composite-Signal auf Magnetband abgelegt ist. Der Komponentenanschluss (rot, grün und blau gefärbt) besteht aus drei Chinchanschlüssen mit je einem Kanal: Y, PB und PR und deren Erdungen (Mantel). Der S-Videoanschluss hat vier Pins, einen für das Luma Signal Y plus dessen Erdung sowie den gemeinsamen Chroma-Pin C für das kombinierte PB,PR-Signal plus dessen Erdung.
Der Composite-Anschluss besteht aus einem einzigen Chinch-Anschluss (gelb).

Je nach Anwendung ist eine Reduktion der Bandbreite nötig, bei anderen Anwendungen ist die Erhaltung der vollen Bildinformation wichtiger. Darum wurden unterschiedliche Standards entwickelt, welche die Bandbreite des Signals als Ganzes verschieden stark reduzieren, nämlich von drei (component) auf zwei Kanäle (S-Video) oder auf einen einzige Kanal (composite). Wiederum wurden technische Tricks angewendet, um auch bei Datenreduktion den Schärfeeindruck des Bildes möglichst gut zu erhalten. Ausgehend vom «Y, PB, PR»-Signal werden die beiden Farbkomponenten PB und PR auf einen gemeinsamen Kanal reduziert, wobei beiden jeweils die Hälfte ihrer ursprünglichen Bandbreite zur Verfügung steht (Y/C). Dieses Vorgehen legte die Grundlage für die digitale 4:2:2-Kompression: ein Kanal mit voller Informationsdichte und zwei mit halber. Da die Helligkeitsinformation Y in voller Auflösung vorhanden bleibt und nur die rote und die blaue Farbinformation reduziert sind, bleibt der Schärfeeindruck des zusammengefügten Bildes recht gut erhalten. Man redet dabei von Bandbreitenreduktion bzw. Farbunterabtastung. Abb. 3 illustriert die Datenreduktion durch selektive Halbierung der horizontalen Auflösung der Differenzsignale CB und CR. Anhand der Darstellungen der U und V-Kanäle ist schon ersichtlich, dass ihr Beitrag zur Bildschärfe klein ist und der Verlust von je 50% der Bildinformation pro Kanal einen kleinen Einfluss auf den Schärfeeindruck des rekombinierten Bildes hat.

Da das analoge PAL-Bild per Definition 576 aktive Bildzeilen enthält, hat die Halbierung der Bandbreite eine Halbierung der horizontalen Auflösung des roten und des blauen Farbkanals zur Folge. Der grüne Kanal kann aus dem Luminanz-Signal in voller Auflösung rekonstruiert werden. Die verschiedenen gängigen Optionen der Farbunterabtastung bei digitalen Bildern werden durch ähnliche Terme beschrieben (4:2:0, 4:1:1 usw.). Eine detaillierte Erklärung der Nomenklatur findet sich bei Poynton (2002).
Wird ein bandbreitenreduziertes Signal unkomprimiert digitalisiert, so ist das Resultat zwar digital «uncompressed», da das Signal aber schon analog reduziert wurde, erhält man natürlich nicht die Qualität einer Digitalisierung ab R, G, B oder Y, PB, PR.
Die auf Bildpunkten basierte Darstellung des digitalen Videobildes steht der zeilenweisen Darstellung im analogen Video gegenüber. Bei der Digitalisierung von analogem Video mittels eines A/D-Wandlers ist die vertikale digitale Auflösung durch die Zeilenzahl eindeutig gegeben. Die horizontale Auflösung jeder Zeile ist jedoch ähnlich zu bestimmen wie bei anderen analogen Bildern wie z. B. Filmmaterial: Aus dem analogen, kontinuierlichen Signal, das zwischen zwei Fixpunkten beliebige Werte annehmen kann, wird eines mit bestimmten, diskreten Stufenwerten. Man muss entsprechend eine Abtastrate und eine Quantisierung bestimmen.
Ist eine Darstellung mit quadratischen Pixeln erwünscht, berechnet sich die horizontale Auflösung über die Zeilenzahl und das Seitenverhältnis: Man erhält für ein PAL-Videosignal einen Wert von 768 horizontalen Bildpunkten. Die Auflösung 768 × 576 (4:3) wird zwar heutzutage auch verwendet, das gängige digitale PAL-Signal wird aber mit einer Auflösung von 720 × 576 (5:4) Bildpunkten und Non-Square Pixeln angegeben.
Codec, Container und Kompression
Das Wort Codec beinhaltet die engl. Begriffe Coder und Decoder. Das Encodieren bezeichnet die Übersetzung einer analogen Information in einen digitalen Code durch einen Codierer und evtl. einen Kompressor; für das Decodieren ist ein Decodierer und bei vorliegender Kompression ein Expander erforderlich. Ein Encoder kann auch eine bereits digital vorliegende Datei bearbeiten, wenn beispielsweise ein Videosignal unkomprimiert digitalisiert oder digital produziert wurde und daraus für die Herstellung einer DVD eine MPEG-Datei herzustellen ist; in diesem Fall spricht man von Transcodierung.
Ein Codec ist eine Anweisung zum Codieren oder Decodieren von Daten mit dem Ziel, die Stream- oder Dateigrösse zu reduzieren. Dies kann entweder verlustfrei oder verlustbehaftet geschehen. Es gibt Codecs für das Bild, für den Ton und für die Untertitel.
Es gibt sehr unterschiedliche, auf bestimmte Anwendungsbereiche (Aufnahme, Schnitt, Streaming, Archivierung usw.) zugeschnittene Codecs für bewegte Bilder, weil die Bedürfnisse (und die zugehörige Hardware) abhängig vom Lebenszyklus eines Videos sind; hinzu kommen aus denselben Gründen noch zahlreiche qualitativ unterschiedliche Varianten und verschiedene Versionen von Codecs. Aufgrund unterschiedlicher Faktoren wie Speicherplatz, Geschwindigkeit der Datenübertragung und -verarbeitung, vorhandene Infrastruktur und den damit verbundenen Kosten ist maximale Qualität in allen Phasen meist nicht möglich.
Die Vielfalt an Codecs und Dateiformaten liegt zudem auch im Interesse der Industrie an proprietären Dateiformaten, die ihr kommerzielle Kontrolle und Abhängigkeiten verschafft.
Kompression dient in erster Linie zur Reduktion der Datenmenge, um eine verringerte Datenrate bei der Übertragung zu erreichen bzw. weniger grosse Dateien zu generieren. Dadurch lassen sich Arbeitsgänge beschleunigen und Speicherplatz einsparen. Dagegen ist die erforderliche Rechenleistung der eingesetzten Infrastruktur höher, was insbesondere bei gewissen sehr komplexen, verlustfrei komprimierenden Codecs wie Motion JPEG 2000 relevant sein kann. Die Frage nach dem Umfang des Bedarfs an Speicherplatz wiederum ist für die sichere Langzeiterhaltung (finanziell) relevant.
Von einer verlustfreien Kompression (engl. «lossless compression») spricht man, wenn die daraus resultierende Datei im Idealfall kleiner ist als die Ausgangsdatei, die Information nach der Codierung aber identisch bleibt und lediglich anders codiert ist. (Siehe Abb. 4)

Ist der Informationsgehalt nach der (Trans-)Codierung kleiner als zuvor, so handelt es sich um eine verlustbehaftete Kompression (engl. «lossy compression»). Oft ist Kompression visuell nicht (einfach) erkennbar, obwohl je nachdem auf der Datenebene massive Informationsverluste durch die Kompression erfolgt sind. Diese sogenannte «visually lossless compression» beruht auf subjektiver Wahrnehmung, es existiert keine Definition. Daher ist diese Art der Kompression nicht geeignet für Archivkopien, sie kommt allenfalls für Benutzungskopien in Frage.
Den meisten Codecs liegt ein Kompressionsalgorithmus zugrunde. Die Algorithmen können sich stark voneinander unterscheiden: So gibt es Verfahren, die Einzelbilder komprimieren (sog. Intraframe-Kompression und solche, die über eine Sequenz hinweg komprimieren (sog. Interframe-Kompression). In Abb. 5 wird die räumliche Kompression erklärt: Im dargestellten Beispiel wird ein Datensatz mit 6 × 6 Bildpunkten mit je vier verschiedenen Grauwerten in 2 × 2 Datensätze unterteilt. Die Grauwerte dieser Datensätze werden rechnerisch vereinheitlicht, woraus ein 3 × 3 Datensatz gebildet wird, der die Hälfte der ursprünglichen horizontalen und vertikalen Auflösung aufweist. Die räumliche Kompression reduziert die Bildinformation nicht gleichmässig über die gesamte Bildfläche, sondern abhängig von der Informationsdichte der Bildanteile mit unterschiedlicher Intensität. Bildbereiche mit hoher Informationsdichte werden weniger stark zusammengefasst als jene mit wenig Bildinformationen (z. B. blauer Himmel).

Je nach Codec ist es möglich, die Kompressionsrate oder die Datenrate einzustellen, weshalb die Angabe des verwendeten Codecs nicht ohne Weiteres auf die Art und die Stärke der verwendeten Kompression schliessen lässt, sondern diese explizit angegeben werden muss. Die Palette an Codecs wird laufend erweitert, um deren Effizienz zu erhöhen und sie neuen Anwendungen anzupassen; auf diesen Umstand geht auch die Obsoleszenzgefahr zurück, die für die Langzeiterhaltung gerade bei Dateien relevant ist. Der Container speichert die vom Codec kodierten Daten in eine Datei und verbindet so Bild, Ton und weitere Informationen (siehe auch Dateiformat, weiter unten). Der Container ist u. a. dafür verantwortlich, dass dem Player die Bild- und die Tondaten synchron geliefert werden. Er koordiniert also die Arbeit des Video- und des Audio-Codecs. Container beinhalten unter anderem folgende Elemente:
-
Video-Codec und -Daten
-
Audio-Codec und -Daten
-
Untertitel-Codec und -Daten
Format
Der Begriff Format wird in der Welt der Medien oft unpräzis und für unterschiedliche Dinge verwendet. Um Verwechslungen und Missverständnisse zu vermeiden, folgen hier präzisierende Begriffsdefinitionen.
Medienformat
Heute werden alle technischen Massenkommunikationsmittel zwischen Menschen allgemein als Medien bezeichnet, etwa der Rundfunk, die Printmedien, das Internet usw. Im audiovisuellen Bereich meint man mit Medium die technische Form des Kommunikationsmittels. Bsp.: Video, Film, Datei
Videoformat
Videoformat ist ein Oberbegriff, der einerseits die verschiedenen Datenträger wie Kassetten und offene Spulen mit ihren jeweiligen Eigenschaften bezeichnet, andererseits auch für Dateien verwendet wird. Letztere werden mit den Begriffen Container und Codec näher spezifiziert
Folgende Grössen und technische Standards definieren ein Videoformat:
-
Speichertyp wie Kassette, offene Spule, Disc usw.
-
Speicherung nach verschiedenen Verfahren: optisch, magnetisch, magnetooptisch.
-
Art der Aufzeichnung, spezifisches Signal (z. B. U-matic Low Band bzw. High Band, DVCAM bzw. DV)
-
Bildfrequenz und Abtastung (Bilder pro Sekunde, engl. Frames per Second, fps, interlaced oder progressiv)
-
Bildgrösse und Seitenverhältnis (SD bzw. HD, UHD) Bsp.: Betacam SP PAL, HDV 1080i oder HDV 720
Bildformat (= Bildseitenverhältnis)
Das Bildformat beschreibt das Verhältnis von Breite zu Höhe eines Bildes (1) sowie die Art der optisch verzerrten Abbildung des Bildes, also sphärisch oder anamorphotisch (2). Zu (2) siehe weiter unten, Beispiele für (1) sind: 16:9, 4:3 (Video), 1,37:1, 1,66:1 (Film). Im Folgenden wird dafür der Begriff «Bildseitenverhältnis» verwendet.
Verschiedene audiovisuelle Medien haben unterschiedliche Seitenverhältnisse. Der Transfer eines audiovisuellen Mediums in ein anderes (z. B. Film → Video) kann einen Transfer in ein anderes Bildseitenverhältnis bedingen. Das gängigste Beispiel für diese Problematik ist der Transfer eines 4:3-Bildes in ein 16:9-Seitenverhältnis. Dies kann auf unterschiedliche Art geschehen:
-
Reinstellen (= Curtains, Pillar Box, mit oder ohne Blurred background sides)
-
Vergrössern und Beschneiden (Bildverlust oben und unten, «croppen»)
-
Pan & Scan (unterschiedlicher Bildverlust)
-
Verzerren (Verlust der korrekten Proportionen).
Jede dieser Lösungen hat bestimmte Vor- und Nachteile. Deren gut informierte Wahl ist anhand der konkreten Anwendung zu fällen. Zufall oder Mangel an Wissen dürfen nicht der Hauptfaktor sein.
Die Wahrung des Seitenverhältnisses und die Überlieferung der gesamten Bildinformation ist für die Erhaltung unerlässlich, darum kommt für Originale mit Seitenverhältnis 4:3 neben dem Beibehalten des Seitenverhältnisses im Erhaltungsmaster nur das Reinstellen in 16:9 in Frage. So bleibt die gesamte Bildinformation im korrekten Seitenverhältnis für eine zukünftige Nutzung erhalten. (Siehe Abb. 6 und 7)
Wird ein Bild ohne Beschnitt oder Verzerrung in ein breiteres Bildformat übertragen, entstehen links und rechts schwarze Balken (Pillar Box oder Curtains), bei der Übertragung in ein weniger breites Bildformat werden oben und unten schwarze Balken hinzugefügt (Letterbox).
Abb. 7 vergleicht die Ausnützung der Filmoberfläche für Filme mit 4:3- und 16:9-Bildseitenverhältnis für die Standards 2K, DCP 2K und Full HD. Die Film- und die Videotechnik hat eine Vielzahl von Film- und Videoformaten hervorgebracht. Die Flexibilität der digitalen Darstellung von Bildern hat die Möglichkeiten und somit die Zahl der Standards noch erweitert. Die Tatsache, dass in den letzten 30 Jahren ein Übergang vom Bildseitenverhältnis 4:3 zu 16:9 im Kino und im Fernsehen stattgefunden hat, schlägt sich in der Komplexität der Standards und Substandards nieder. Abb. 6 gibt einen Überblick über die gängigen Videostandards von Standard Definition (SD) und High Definition (HD) und deren Auflösung in Pixeln. Oft stimmt das Seitenverhältnis in Pixeln nicht mit dem Seitenverhältnis in der Darstellung überein.
In der Filmtechnik wurden mit der aufkommenden Digitalisierung der 2K- und der 4K-Standard für das abgetastete Filmbild definiert. 2K und 4K beziehen sich auf die maximale Fläche eines 35-mm-Filmbildes zwischen den Perforationen und weisen 2056 bzw. ca. 4112 horizontale Pixel auf. Das klassische 35-mm-Bild, das sich über 4 Perforationen erstreckt, hat ein Seitenverhältnis von 4:3 und man erhält entsprechend 2056 × 1536 Pixel für 2K und 4112 × 3072 Pixel für 4K. Die modernen digitalen Projektionsstandards für das Kino werden auch 2K DCP und 4K DCP genannt, beziehen sich aber auf ein Bild, das nahe dem Bildseitenverhältnis 16:9 ist. Sie weisen 2056 × 1080 Pixel für 2K und 4112 × 2160 Pixel für 4K auf. Dies kann zu Verwirrung führen, denn die beiden Optionen 2K und 4K sind nicht für dasselbe Bildseitenverhältnis optimiert.


Sphärisch
Eine sphärische Optik bildet Objekte im Gegensatz zu einer anamorphotischen Optik unverzerrt ab. Diese Optiken werden sphärisch genannt, da die Form ihrer beiden Oberflächen dem Oberflächenausschnitt einer Kugel entspricht und somit unter anderem rotationssymmetrisch ist. Griechisch: Sphaira = Ball, Kugel, Himmelskugel.
Bei sphärischen Linsen treten Abbildungsfehler wie die sogenannte sphärische Aberration auf. Solche Effekte werden in modernen Linsen durch leichte Korrekturen der Oberflächenform auskorrigiert. Die so erzeugten Linsen nennt man asphärisch. Sie weichen in ihrer Form im Gegensatz zu den anamorphotischen Linsen aber nur leicht von der Kugeloberflächenform ab.
Kinofilmkopien werden auf Englisch hin und wieder als «spherical 35 mm prints» bezeichnet. Damit sind gängige Kopien gemeint, die ohne anamorphotische Linse korrekt projiziert werden können. Ein «Spherical Print» eines CinemaScope-Films ist entweder horizontal auf ein 4:3 oder Widescreen Seitenverhältnis beschnitten, oder mit verkleinerter Bildfläche «letterboxed» aufbelichtet.
Anamorphotisch
Der Ausdruck anamorphotisch geht auf griechischen Begriff anamorph zurück und bedeutet sinngemäss «umgestaltet». Er bezeichnet in der Optik Objektive, welche die Abbildung eines Objekts verzerren.
In der klassischen Filmtechnik werden hauptsächlich anamorphotische Objektive verwendet, welche das Bild in einer Richtung stauchen oder dehnen. So können Breitbildformate wie CinemaScope in bestmöglicher Qualität auf 35-mm-Film belichtet und im vorgesehenen Seitenverhältnis projiziert werden. (Siehe Abb. 8)
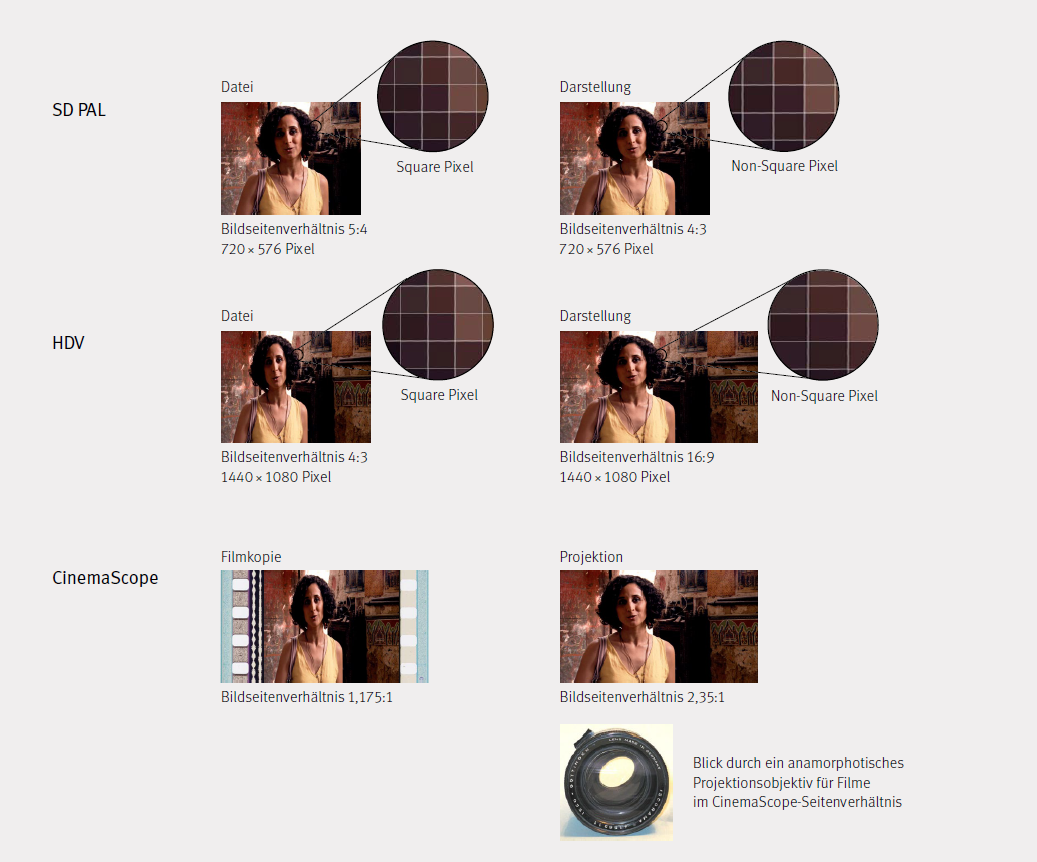
Der 35-mm-Film mit optischer Tonspur sieht eine maximale Bildfläche von 21,9 mm Breite und 18,6 mm Höhe für die Belichtung des Bildes vor. Dies entspricht einem Seitenverhältnis von 1,18:1. Das CinemaScope-Bild mit 2,35:1 Seitenverhältnis kann erzeugt werden, indem bei der Aufnahme eine Optik verwendet wird, welche das Bild bei der Belichtung im Verhältnis 2:1 horizontal staucht und in der Projektion eine solche, welche das Bild im Verhältnis 1:2 horizontal dehnt. Das unverzerrte Aufbelichten eines Bildes mit den Seitenverhältnissen 2,35:1 würde zu einer äusserst schlechten Ausnützung des Bildbereichs führen (Letterbox).
In der digitalen Aufnahme und Wiedergabe von Bewegtbildern wurde die beschriebene Strategie übernommen. Da das Seitenverhältnis der Sensoren in Kameras oft nicht mit den sich ändernden Anforderungen an das Seitenverhältnis des Ausgabeformats übereinstimmt oder damit Kameras unterschiedliche Seitenverhältnisse aufnehmen können, wurden verschiedene Ansätze entwickelt. Dabei kommen einerseits ebenfalls anamorphotische Optiken zur Anwendung, aber auch das Verzerren und Entzerren von Bildern durch digitales Skalieren. Bei digitalen Bildern, die in einem anderen Seitenverhältnis gespeichert als sie dargestellt werden, spricht man auch von Non-Square Pixeln.
Videos die in einem anderen Seitenverhältnis gespeichert sind, als sie dargestellt werden sollen, werden normalerweise von der Playersoftware beim Abspielen durch digitales Skalieren in das korrekte Seitenverhältnis gebracht. Der Player ist hierfür auf Metadaten mit Information zum Seitenverhältnis der Darstellung angewiesen. Diese Information kann im Header der Datei gespeichert sein oder in den Metadaten des Containers. Es kann vorkommen, dass diese Informationen nicht übereinstimmen. Je nach Player wird die eine oder andere Information verwendet resp. prioritär behandelt.
Square und Non-Square Pixel
Pixel sind grundsätzlich die quadratischen Grundbausteine eines digitalen Bildes. Pixel besitzen einen Graustufen- oder Farbwert. Das Seitenverhältnis eines in Pixel dargestellten Bildes ergibt sich aus der vollen Anzahl Pixel in der Breite zu der vollen Anzahl Pixel in der Höhe, dividiert durch den grössten gemeinsamen Teiler der Zahlen:
z. B. «Full HD»: Breite: 1920 Pixel, Höhe 1080 Pixel
= 1920/120:1080/120
= 16:9
Gewisse Videoformate werden in Form von Dateien jedoch nicht in dem Pixel-Seitenverhältnis gespeichert, in dem sie dargestellt werden.
z. B. SD PAL: Breite: 720 Pixel, Höhe: 576 Pixel
= 720/144:576/144
= 5:4
Darstellungsseitenverhältnis: 4:3.
In diesem Fall redet man von Non-Square Pixeln, da die Pixel in der Darstellung horizontal auseinandergezogen werden müssen, um von der 5:4- auf die 4:3-Darstellung zu kommen. Das Mass der Streckung beträgt im Fall von SD PAL 6,66 %. Die Informationsdichte im Bild bleibt dieselbe, die Pixel sind aber nicht mehr quadratisch, sondern rechteckig.
Die Gründe, warum diese Darstellungsform angewendet wird, hat bei SD PAL seinen Ursprung in der klassischen Videotechnik. Bei HD-Videoformaten ist es eine weitere Form der Einsparung von Information, also eine Form der Kompression.
Grundsätzlich stellen heute alle gängigen Projektoren und Monitore digitale Bilder immer mittels quadratischer Pixel dar. Wenn die Datei rechteckige Pixel beinhaltet, muss sie die Grafikkarte umrechnen.
Dateiformat
Der digitale Code, in dem die enthaltene Information gespeichert ist. Die Kenntnis des Dateiformats ist essenziell für die Interpretation der in einer Datei abgelegten Information. Die Inhalte digitaler Dateien lassen sich durch reines Betrachten der Daten nicht identifizieren. Es braucht also immer eine Übersetzungshilfe, um zu erkennen, um welche Inhalte es sich handelt. Ohne diese Identifikation (sei sie nur eine Dateiendung wie z. B.: .dv, .bmp) und eine geeignete Infrastruktur ist die Information nur ein nutzloser Haufen Binärzahlen. Moderne Betriebssysteme ordnen Dateien über Dateiformate Anwendungen zu, welche die Dateien interpretieren können.
Es gibt Dateiformate, die einen Container (oder Wrapper) bezeichnen. Im audiovisuellen Bereich können Container unterschiedliche Codecs und Streams fassen, d. h. Bild und Ton in unterschiedlichen Codecs sowie zusätzliche Informationen wie Timecodes, Untertitel und Metadaten, je nach Art und Flexibilität des Containers.
Nur selten liegen reine Dateiformate vor, wie z. B. ein AIFF (.aif) oder ein DV (.dv). Meist handelt es sich um einen Container wie z. B. ein PCM-Ton in einem Wave-Container mit der Dateiendung .wav oder um ein Video im DV-Codec in einem QuickTime-Movie-Container mit der Dateiendung .mov. Containerformate werden mit dem Ziel verwendet, verschiedene Elemente (z. B. verschiedene Codecs, Einzelbilder, Timecodes) in einer einzigen Datei speichern zu können, um multimediale Darstellungen zu ermöglichen. Ein für die Archivierung spezifischer Grund kann auch das Speichern von begleitenden Dateien wie z. B. Textdateien mit Metadaten in einem Container zusammen mit Bild- und Tondateien sein; dies lässt z. B. der MXF-Container zu, aber nicht alle Containerformate bieten dahingehend dieselben Möglichkeiten.
Allgemein ist festzuhalten, dass – genau so wie bei der Wahl des geeigneten Codecs – die verwendeten Container bewusst ausgewählt werden sollten, damit sie gut zu der vorhandenen oder vorgesehenen IT-Infrastruktur (Betriebssystem, Abspiel- und Bearbeitungssoftware, usw.) passen. Der QuickTime-Player wird beispielsweise seit Mitte 2016 auf Windows-Betriebssystemen nicht mehr unterstützt. Für die Wiedergabe von Videos in QuickTime-Movie-Containern (.mov) muss auf andere Software-Player ausgewichen werden, welche je nachdem nicht alle ursprünglichen Funktionalitäten unterstützen. Auch sollten Wechsel von einem Container zu anderen – wie auch Transcodierungen – sehr gut kontrolliert werden, weil dabei immer Gefahr besteht, dass wichtige Metadaten (z. B. Seitenverhältnis oder Farbraum), Elemente (z. B. Timecode) oder gewisse Eigenschaften (z. B. Bildfrequenz) verloren gehen.
Es ist kaum möglich, eine Übersicht über alle relevanten Eigenschaften von Containern und dem Umgang der jeweiligen Player damit zu geben. Es ist allerdings empfehlenswert, verschiedene Container und Player mit deren Möglichkeiten, verschiedene Kombinationen usw. zu testen und evaluieren.
Die verschiedenen Software-Player unterscheiden sich in ihren spezifischen Funktionalitäten wie Vor- und Rücklauf, Ansteuerung von Einzelbildern, Darstellung des Audiopegels, Darstellung des Timecodes und anderen spezifischen Darstellungsoptionen. Neben den Unterschieden in der Funktionalität kann sich auch die Darstellung selbst je nach Kombination von Software-Player, Codec und Container unterscheiden. Abb. 9 visualisiert, dass Software-Player unterschiedliche Priorisierungen der Metadaten beispielsweise des Videocodecs versus der Metadaten des Containers aufweisen können. So kommt es zum Beispiel zu einer unterschiedlichen Darstellungsbreite der identischen Datei.
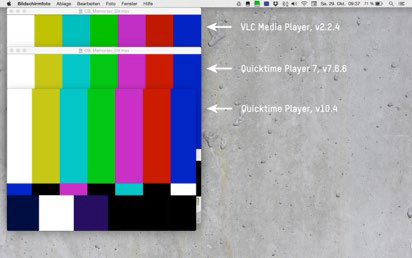
Abb. 10 zeigt ein anderes, wesentliches Unterscheidungsmerkmal der verschiedenen Software-Player: Die spezifischen Codec-Bibliotheken, auf welche diese Player zurückgreifen. Diese sind u. a. für die Unterschiede in der Farbdarstellung einer identischen Datei zurückzuführen.

Archivformat, Benutzungsformat
Der Lebenszyklus eines audiovisuellen Werks kann grob folgenden Arbeitsbereichen zugewiesen werden: Aufnahme, Postproduktion, Distribution/Vorführung und Archivierung. Jeder Bereich verfügt über eine auf ihn zugeschnittene Palette an Dateiformaten. Diese werden den Arbeitsbereichen folgendermassen zugeteilt:
Aufnahmeformat
Das Dateiformat oder das physische Videoformat, in dem beim Dreh bzw. der Videoaufnahme die Bilder aufgezeichnet werden. Das Aufnahmeformat bestimmt den grösstmöglichen Rahmen der Bildqualität und Ästhetik.
Postproduktionsformat
Dateiformate, in denen das Video bearbeitet wird (Schnitt, Lichtbestimmung, Spezialeffekte usw.), deshalb auch Bearbeitungsformat genannt. Die ursprünglich vorhandene Qualität des Materials kann in der Postproduktion von ungeeigneten Programmen und Codecs beeinträchtigt werden. Das schwächste Glied in der Kette bestimmt die Qualität des Endprodukts. Im Idealfall wird in keinem Schritt der Nachbearbeitung die Qualität des Aufnahmeformats unterschritten. Im Zusammenhang mit der Archivierung wird von Mezzanine-Formaten gesprochen, die nicht die gesamte Information beinhalten, aber dennoch so viel, dass man sie weiterbearbeiten kann (z. B. Licht bestimmen oder schneiden), ohne dass dadurch im Bild sichtbare Fehler auftreten. Klassisch etablierte Mezzanine-Formate sind beispielsweise Apple ProRes 422 HQ und ProRes 4444 oder Avid DNxHD und DNxHR 444.
Nutzungsformat
Können verschiedene, in der Regel stark komprimierte Dateiformate sein, die für die Sichtung in einem bestimmten Zusammenhang optimiert wurden; sei es für den Vertrieb und die Vorführung in Kinos, die Ausstrahlung im Fernsehen, Projektionen im öffentlichen Raum oder zu Hause oder die Konsultation via Web. Die Qualität kann entsprechend von IMAX-Kino- Niveau bis zu sehr bescheidener YouTube-Qualität variieren. Das Nutzungsformat erlaubt zum Beispiel die Sichtung in der korrekten Geschwindigkeit, kann aber nicht oder nur schlecht weiterbearbeitet werden; eine neue Lichtbestimmung (Farbkorrektur) etwa wäre kaum möglich. Es sind je nach Zusammenhang unterschiedliche Begriffe gebräuchlich: In Kinematheken/Kinos und Museen wird meist ein Begriff wie Vorführ-, Projektions-, Distributionsformat oder -kopie («dissemination copy») verwendet, im Archivbereich Nutzungs-, Zugangs-, Konsultations- oder Sichtungskopie, wenn nicht allgemeiner und nach OAIS von DIPs gesprochen wird.
Archivformat
Ein Dateiformat, in dem Video-, Film- und Tondokumente gespeichert und gepflegt werden, um möglichst lange Zeit nutzbar zu bleiben. Im Archivformat wird der Konservierungs- oder Archivmaster, also die im Archiv langfristig zu sichernde Datei, abgelegt. Es sollte idealerweise die gesamte Information enthalten sein, die während der Digitalisierung erzeugt wurde. Da aber Filmscanner proprietäre Zwischenformate erzeugen, sollten diese in ein standardisiertes Format umgewandelt werden. Im Filmbereich wird heute meistens der Farbraum RGB mit der Unterabtastung 4:4:4 verwendet, während im Video- und Fernsehbereich Y′CBCR 4:2:2 die Regel ist. Für das Archivformat ist es auch wichtig, genau zu dokumentieren, «wo» sich das Weiss im Farbraum befindet.
Achtung: Archivmaster sind keine Vorführelemente. Jede Vorführung/Benutzung führt zu einer Abnutzung des Masters bzw. birgt das Risiko der Entstehung von Fehlern oder Schäden durch unsachgemässe Handhabung (Datenverluste).
Bibliographie
-
Poynton, Charles, Chroma subsampling notation, o. O., 2002. Online, Stand: 4.2.2025
Letzte Anpassung: Februar 2025